مجله مطالب خواندنی
سبک زندگی، روانشناسی، سلامت،فناوری و ....مجله مطالب خواندنی
سبک زندگی، روانشناسی، سلامت،فناوری و ....خواندن مغز انسان با هوش مصنوعی امکانپذیر است
[ad_1]در چند سال گذشته آزمایشگاه علوم اعصاب جک گلنت یک سری مقالات تحقیقی منتشر کرده است که ابتدا بیاهمیت به نظر میرسیدند.
در سال ۲۰۱۱، این آزمایشگاه نشان داد که میتوان با رصد فعالیتهای مغزی افرادی که در حال تماشای فیلم سینمایی هستند، کلیپهای ویدیویی همان فیلم را دوباره ساخت. به عبارت دیگر میتوان مدعی شد که استفاده از رایانه برای بازآفرینی تصاویر یک فیلم، تنها از روی فعالیتهای مغزی کسی که در حال مشاهدهی آن است، یک نوع ذهنخوانی به شمار میآید. در سال ۲۰۱۵، تیم تحقیقاتی گلنت در طی آزمایشی با موفقیت توانستند حدس بزنند که افراد مشارکتکننده در آزمایش دقیقا به کدام نقاشی معروف فکر میکنند.
امسال، این تیم در نوشتهای در ژورنال Nature اعلام کرد که تنها با مطالعه بر مشارکتکنندگانی که در حال گوش کردن به فایلهای صوتی بودند، توانستند یک اطلس شامل بیش از ۱۰ هزار کلمهی منفرد مستقر در مغز را ایجاد کنند.
اما پرسش این است که آنها چطور این کار را انجام دادند؟ در پاسخ باید بگوییم که با استفاده از روش یادگیری ماشین؛ یعنی نوعی هوش مصنوعی که با استخراج و تحلیل تودههای عظیم اطلاعات مغزی، الگوی نهفته در فعالیتهای مغزی را یافته و تفکرات و ادراک انسان را پیشبینی میکند.
هدف محققان این آزمایشگاه، ساخت دستگاه ذهنخوان نیست، گرچه بسیاری به اشتباه چنین تصوری دارند. عصبشناسان نمیخواهند کلمات عبور شما را از ذهنتان بدزدند، همچنین آنها به دانستن تاریکترین رازهای زندگیتان علاقهمند نیستند. هدف واقعی چیزی فراتر از این موضوعات است. جک گلنت و دیگر عصبشناسان در پی این هستند تا با استفاده از ماشین برای استخراج حجم زیادی از اطلاعات مغزی و تبدیل علوم اعصاب به علوم دادههای بزرگ، نحوهی درک ما از فعالیتهای مغزی را دگرگون کنند.
تا جایی که میدانیم، مغز انسان پیچیدهترین شی موجود در عالم است و درک ما از نحوهی فعالیت آن نیز بسیار اندک است. ایدهی جالب جک گلنت که میتواند شاخهی علوم اعصاب را از مرحلهی ابتدایی خود به سمت جلو هدایت کند به این صورت است:
شاید لازم است یک دستگاه بسازیم تا بتواند نحوهی فعالیت مغز را برای ما آشکار کند. ما امیدوار هستیم که با رمزگشایی از الگوهای درهمتنیدهی مغزی، راهی برای درمان بیماریهای مغزی پیدا کنیم.
هم اکنون ابزار اصلی برای مطالعه و تحلیل آناتومی مغزی و فعالیتهای آن، MRI است. این تکنولوژی از دههی ۹۰ میلادی مورد استفاده قرار میگیرد و عکسهای گرفته شده توسط آن ناواضح و سطحی است.
برای درک قابلیتهای روش fMRI دانستن این نکته خالی از لطف نیست که کوچکترین واحد فعالیت مغزی که توسط این روش تشخیص داده میشود، یک وکسل (Voxel) است. معمولا وکسلها از یک مکعب با ابعاد یک میلیمتر کمی کوچکتر هستند. ممکن است در داخل یک وکسل بیش از ۱۰۰ هزار عصب وجود داشته باشد. آنطور که تال یارکونی، یک عصبشناس از دانشگاه تگزاس توضیح میدهد، fMRI مانند این است که بر فراز یک شهر پرواز کنید و ببینید که در چه مکانهایی چراغها روشن هستند.
عکسهای مرسوم fMRI میتواند به ما نشان دهد که چه مناطقی از مغز در فعالیتهای خاص، نقش حیاتی دارند، برای مثال، میتوان تشخیص داد که چه ناحیهای از مغز احساسات منفی را پردازش میکند، یا چه نواحی از مغز هنگام دیدن یک چهرهی آشنا روشن (فعال) میشوند. اما نمیتوان دریافت که آن ناحیه از مغز دقیقا چگونه در رفتارهای انسان نقش دارد و اینکه آیا نواحی دیگر مغزی که روشن نشدهاند، نقش کلیدی در رفتارهای خاص دارند یا نه. مغز مانند یک شی ساخته شده توسط لگو نیست، یعنی این طور نیست که نواحی مغزی مانند تکتک لگوها نقش مشخصی داشته باشند. مغز متشکل از یک شبکه از فعالیتها است. جک گلنت میگوید:
هر ناحیه از مغز، ۵۰ درصد احتمال دارد که با ناحیهی دیگر در ارتباط باشد.
به همین دلیل است که تلاشها برای یافتن، مثلا مرکز گرسنگی یا احتیاط، به نتایج قانعکنندهای ختم نشده است.
پیتر بندتینی، رییس دپارتمان روشهای fMRI در انجمن ملی سلامت روانی (National Institute of Mental Health) میگوید:
ما سالهاست که به این لکههای ظاهر شده در عکسهای fMRI نگاه میکنیم و به این موضوع فکر میکنیم که چه اطلاعاتی در آنها نهفته است. اکنون مشخص است که هر تغییر کوچکی در این لکهها، حاوی اطلاعات در مورد عملکرد مغز است، اطلاعاتی که ما تا کنون قادر به کشف آنها نبودهایم. به همین دلیل است که ما به تکنیکهای یادگیری ماشین نیاز داریم. چشمان ما میتواند لکهها را ببیند، اما نمیتوانیم الگوها را ببینیم. این الگوها بسیار پیچیده هستند.
در اینجا یک مثال ارائه میدهیم. بهطور سنتی این طور تصور میشود که پردازش زبان در نیمکرهی چپ مغز و در دو ناحیهی مشخص، ناحیهی Broca و ناحیهی Wernicke اتفاق میافتد. اگر این ناحیههای صدمه ببینند، شما در درک یا ایجاد زبان با مشکل روبهرو میشوید.
اما الکس هاث، فوقدکترای عصبشناسی در آزمایشگاه گلنت نشان داد که این درک ما از کارکرد مغز در ارتباط با زبان، بسیار ساده و سطحی است. او تصمیم گرفت دریابد که آیا کل مغز در درک زبان نقش دارد یا نه.
در یک آزمایش، او از شرکتکنندگان در یک تحقیق خواست تا به یک داستان صوتی گوش دهند. همزمان او و همکارانش فعالیتهای مغزی آنها را توسط اسکنرهای fMRI ضبط کردند. هدف از این آزمایش پی بردن به ارتباط نواحی مختلف مغز در حین فعالیت مغزی مرتبط با گوش کردن به لغات بود.
گلنت میگوید که چنین آزمایشی اطلاعات بسیار زیادی را تولید میکند، حجمی از اطلاعات که احتملا انسان تا کنون با آن مواجه نشده است. اما به یک نرمافزار رایانهای آموزش داده شد تا با بررسی این اطلاعات، الگوی آنها را بیابد. در نهایت برنامهای که توسط هاث طراحی شده بود توانست یک اطلس از لغاتی که در مغز انسان «زندگی» میکنند را آشکار کند. گلنت در این ارتبط میگوید:
آزمایش الکس نشان داد که قسمتهای زیادی از مغز در درک معنایی لغات نقش دارند.
الکس هاث همچنین نشان داد لغاتی که از لحاظ معنایی به یکدیگر نزدیک هستند، مانند سگ و پودل (نوعی سگ پشمالو)، در نواحی مجاور در داخل مغز جای میگیرند.
پس اهمیت پروژههای این چنینی چیست؟ در دنیای علم، پیشبینی برابر است با قدرت. اگر دانشمندان بتوانند پیشبینی کنند که چگونه یک سری فعالیتهای گیجکنندهی مغزی به تفسیر و درک زبان مربوط میشود، آنگاه میتوانند مدل بهتری از نحوهی کارکرد مغز ارائه دهند و اگر آنها بتوانند یک مدل بهتر بسازند، بهتر میتوانند بفهمند که چرا و چگونه متغیرهای مغز تغییر میکنند، یا به عبارت دیگر مغز دچار بیماری میشود.
یادگیری ماشین چیست؟
یادگیری ماشین مفهومی گستردهای است که شامل استفاده از طیف زیادی از نرمافزارهای رایانهای میشود. به زبان عامیانه، تکنولوژی یادگیری ماشینی که به سرعت در حال توسعه است، به معنای تشخیص و دیدن اشیا توسط ماشینها و با استفاده از فوتونها است که در سطحی نزدیک سطح دید انسان روی میدهد. با استفاده از نوعی تکنولوژی یادگیری ماشین با نام تکنولوژی یادگیری عمیق، سرویس ترجمه گوگل، که قبلا ترجمههای ابتدایی و گاهی خندهآوری ارائه میداد، اکنون میتواند رمانهای ارنست همینگوی را به چند زبان دیگر در سطحی ترجمه کند که با ترجمههای مشهور آنها رقابت کند.
اما اساسا برنامههای یادگیری ماشین به دنبال کشف الگوها و رابطهی بین x و y هستند. معمولا برنامههای یادگیری ماشین ابتدا باید توسط یک سری دادهی تحت «آموزش» قرار گیرند. در این فرآیند، برنامه باید به دنبال الگوی موجود در دادهها بگردد. هر چه میزان دادههای آموزشی بیشتر باشد، برنامه باهوشتر و دقیقتر عمل میکند. بعد از اتمام پروسهی آموزش، دادههای جدیدی به برنامه داده داده میشود. در نتیجه با استفاده از دادههای جدید، برنامههای یادگیری ماشین میتوانند شروع به پیشبینی کنند.
یک نمونهی ساده و جالب این برنامهها، قابلیت فیلتر کردن ایمیلهای اسپم است. برنامههای یادگیری ماشینی با بررسی ایمیلهای اسپم و پی بردن به نحوهی نگارش و ساختار و محتوای آنها، میتوانند از میان ایمیلهای دریافتی، ایمیل اسپم را شناسایی و فیلتر کنند.
لازم نیست که برنامههای یادگیری ماشینی همگی پیچیده باشند، یک برنامهی یادگیری ماشین ممکن است تنها وظیفهی رگراسیون ریاضیاتی را داشته باشد، یا ممکن است به اندازهی DeepMind شرکت گوگل، که روزانه میلیونها داده دریافت میکند، پیچیده باشد. گوگل با استفاده از این برنامه توانست رایانهای بسازد که انسان را در بازی گو (Go) شکست دهد. گفتنی است بازی گو متشکل از یک تخته و دو دسته مهرهی سیاه و سفید است. این بازی به ظاهر ساده، چنان پیچیده است که وضعیتهای محتمل پیش آمده در بازی، از تعداد اتمهای موجود در کیهان بیشتر است.
عصبشناسان از تکنولوژی یادگیری ماشینی به دو منظور استفاده میکنند: کدگذاری و کدشکنی. در روند کدگذاری، برنامهی یادگیری ماشین سعی میکند تا الگوی فعالیت مغزی ایجاد شده توسط یک محرک را پیشبینی کند. اما کدشکنی برعکس مفهوم قبلی است، یعنی نگاه کردن به فعالیتهای مغزی برای پیشبینی این که شرکتکنندگان در حال نگاه کردن به چه چیزی هستند. همچنین عصبشناسان میتوانند از چنین برنامههایی در اسکنهای مغزی، مانند EEG و MEGS استفاده کنند.
برایس کول، عصبشناس از دانشگاه اورگان، اخیرا توانست با استفاده از روش کدشکنی و توسط دادههای به دست آمده از fMRI، چهرههایی که شرکتکنندگان در تحقیق به آنها نگاه میکردند را بازسازی کند.
آن قسمتهایی از نواحی مغزی که کوهل توسط MRI هدف قرار داده بود، به طور سنتی به عنوان مرکز «خاطرات واضح» شناخته شدهاند. کوهل در این ارتباط میگوید:
آیا آن ناحیه شامل جزییات چیزی است که به آن نگاه میکنید؟ یا فقط به این دلیل است که به حافظهی خود اعتماد دارید؟
این که برنامهی یادگیری ماشین بتواند از روی فعالیتهای مغزی ویژگیهای چهرهها را تشخیص دهد به این معنی است که آن نواحی حاوی جزییاتی از «آن چیزی که میبینید» هستند.
به طور مشابه، آزمایشی که توسط گلنت برای پیشبینی نقاشی که شرکتکنندگان به آن فکر میکردند، طراحی شده بود، حاوی یک راز کوچک در مورد ذهن انسان است: ما همان نواحی مغزی را هنگام یادآوری ویژگیهای بصری فعال میکنیم که هنگام دیدن آنها فعال میکنیم.
عصبشناسان عقیده دارند که تکنولوژی یادگیری ماشین هنوز منجر به ظهور انقلاب در رشتهی آنها نشده است. آنها علت این امر را میزان کم اطلاعات در دسترس میدانند. اسکنهای مغزی بسیار زمانبر و هزینهبر هستند و تحقیقات انجام شده در این حوزه شامل تنها چند شرکتکننده میشود و نه چند هزار. اونیل هیومن، محقق نئورودینامیک از دانشگاه پیتزبورگ میگوید:
در دههی ۹۰ و زمانی که علوم اعصاب کمکم شروع به رشد میکرد، مردم سوالهای طبقهبندی-محور میپرسیدند، مثلا اینکه چه نواحی از مغز هنگام نگاه کردن به صورتها فعال میشود، چه نواحی هنگام نگاه کردن به اشیا فعال میشد و یا در مورد خانهها چطور؟ اما ما اکنون میتوانیم سوالهای حسابشدهتری بپرسیم، مانند این سوال: آیا این خاطره که شخصی هماکنون در حال یادآوری آن است، همان چیزی است که او ۱۰ دقیقه پیش به آن فکر میکرد؟
هیومن میگوید که این پیشرفت انقلابیتر و تکاملیتر است.
دانشمندان علوم اعصاب امیدوارند یادگیری ماشین به آنها در تشخیص و درمان اختلالات ذهنی کمک کند. هماکنون روانپزشکان نمیتوانند یک بیمار را در دستگاه MRI قرار دهند و تنها با اتکا به فعالیتهای مغزی تشخیص دهند که او دچار یک نوع بیماری روانی، مانند اسکیزوفرنی است. آنها برای تشخیص بیماریها باید به صورت بالینی با بیماران صحبت کنند، که البته بیشک بسیار ارزشمند است. اما یک روش تشخیص مبتنی بر ماشین میتواند به راحتی بیماریهای روانی را از یکدیگر تشخیص دهد و تاثیر مهمی بر روند درمان بیماری داشته باشد. بندتینی میگوید که برای انجام این کار به اطلاعات MRI بسیار زیادی، در حدود ۱۰ هزار عکس از لکهها، نیاز است.
برنامههای یادگیری ماشین میتوانند با جستجوی الگوهای فعالیتهای مغزی مربوط به بیماران روانی، این اطلاعات را از مغز انسان استخراج کنند. بندتینی در این مورد توضیح میدهد:
شما میتوانید با استفاده بالینی از این برنامهها، بیمار را در اسکنر قرار دهید و بگویید که برمبنای ۱۰ هزار پایگاه دادهی موجود، این بیمار مبتلا به، مثلا اسکیزوفرنی است.
تلاشها برای انجام این کار هنوز در مراحل مقدماتی قرار دارد و تا کنون نتایج محکم و مستندی به دست نیامده است. دان یامینز، عصبشناس و متخصص در علوم رایانهای از دانشگاهMIT میگوید:
اگر به درک کافی از ارتباط بین شبکههای مغزی برسیم، ممکن است که به جایی برسیم که هنگام بروز اختلال در مغز، مداخلات پزشکی مثبت و پیچیدهتری در مغز داشته باشیم. مثلا ممکن است که یک کاشت (implant) در مغز کار انجام دهیم تا به نحوی به بهبود بیماری پارکینسون یا آلزایمر کمک کند.
همچنین روش یادگیری ماشینی میتواند به روانپزشکان کمک کند که پیشبینی کنند چگونه مغز بیماران مبتلا به افسردگی به داروهای خاص واکنش نشان خواهند داد. یامینز در این ارتباط توضیح میدهد: هماکنون روانپزشکان باید از دیدگاه تشخیصی حدس بزنند که یک بیمار چطور به داروها واکنش نشان خواهد داد. چرا که علایم و نشانههای بیماری نمیتواند به طور کامل نشانگر اتفاقات جاری در مغز باشد.
یامینز تاکید میکند که استفاده از یادگیری ماشین برای تشخیص و درمان بیماریها در آیندهی نزدیک روی نخواهد داد. با این حال دانشمندان و محققان سرتاسر جهان در حال کار بر روی این موضوع هستند. اخیرا ژورنال Neurolaimage یک شمارهی کامل را به مقالاتی اختصاص داد که در مورد پیشبینی تفاوتهای مغزی افراد بر مبنای دادههای عکسبرداری عصبی بودند. کارهای اینچنینی بااهمیت هستند. چون زمانی که این کارها عملا وارد حوزهی سلامت شوند، میتوانند منجر به ایجاد روشهای جدید درمان یا پیشگیری شوند.
یادگیری ماشین میتواند تشنجهای صرعی را پیشبینی کند
بیماران مبتلا به صرع هیچگاه نمیدانند که چه زمانی دچار تشنج میشوند. کریستین مایزل، عصبشناسی از انیستیتو ملی سلامت میگوید:
این یک مشکل بزرگ است، شما نمیتوانید رانندگی کنید، چون استرس این موضوع شما را ناراحت میکند. آن طور که میخواهید نمیتوانید کارهای روزمره را انجام دهید. در حالت ایدهال شما میخواهید که یک سیستم هشدار در مورد تشنج قریبالوقوع داشته بشید.
روشهای درمانی کاملی نیز برای بیماری صرع وجود ندارد. بعضی از بیماران، داروهای ضد صرع به صورت ۲۴ ساعته مصرف میکنند، اما این داروها دارای عوارض جانبی بعضا خطرناکی هستند. حتی در ۲۰ تا ۳۰ درصد بیماران، هیچ دارویی از تشنج جلوگیری نمیکند.
اما پیشبینی تشنج میتواند تغییر بزرگی ایجاد کند. اگر یک شخص مبتلا به صرع بداند که در لحظات آینده دچار تشنج خواهد شد، میتواند خود را سریعتر به یک مکان امن برساند و یا از دیگران کمک بگیرد. همچنین پیشبینی تشنج میتواند روشهای درمانی جدیدی را معرفی کند. مثلا سیستم هشدار میتواند باعث فعال شدن ابزاری برای وارد کردن داروی فوری ضدصرع به بدن بیمار شود، یا با فرستادن یک سیگنال از وقوع تشنج جلوگیری کند.
تصویر زیر نوار مغزی یک بیمار صرعی است که توسط مایزل به اشتراک گذاشته شده است. او میگوید:
هیچ تشنجی دیده نمیشود. اما سوال این است که آیا این فعالیت مغزی مربوط به یک ساعت قبل از تشنج است و یا چهار ساعت قبل از آن؟
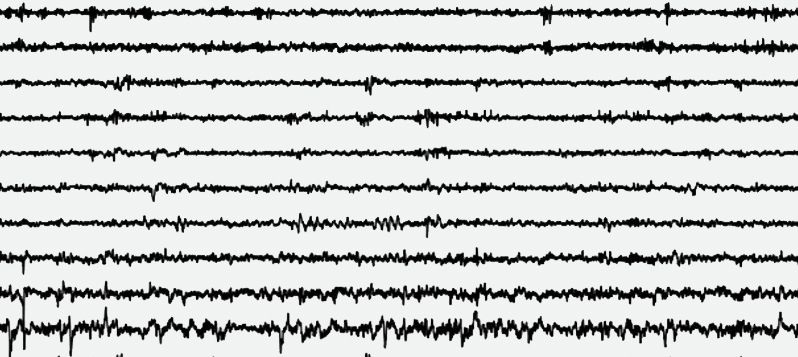
او میگوید که پاسخ به این سوال برای یک پزشک بالینی اگر غیرممکن نباشد، بسیار دشوار خواهد بود.
اما اطلاعات مربوط به تشنج بعدی ممکن است در میان این نوار مغزی پنهان شده باشد. برای آزمایش این احتمال، آزمایشگاه مایزل در یک رقابتی که توسط Kaggle برگزار شده بود، شرکت کرد. Kaggle یک جامعهی علوم آماری است که به صورت آنلاین فعالیت دارد. Kaggle اطلاعات مربوط به نوارمغزی سه بیمار صرعی را در مدت زمان چند سال جمع آوری شده بود، با شرکتکنندگان به اشتراک گذاشت. مایزل از روش یادگیری عمیق برای آنالیز دادهها به منظور پیدا کردن الگوها استفاده کرد.
اما این برنامه تا چه اندازه در پیشبینی تشنج دقیق عمل میکند؟ مایزل در این مورد اینگونه توضیح میدهد: اگر شما یک سیستم کاملا دقیق داشته باشید که همهچیز را بهدرستی پیشبینی میکند، نمرهی ۱ میگیرید، اما اگر سیستم شما به صورت تصادفی اقدام به پیشبینی کند، نمرهی ۰.۵ به شما تعلق میگیرد. ما هماکنون به نمرهی ۰.۸ رسیدهایم. به این معنی که پیشبینی ما دقیق نیست، اما از حالت تصادفی بسیار بهتر است. البته این روش راه زیادی برای گذر از حالت نظری و ورود به عالم واقعی در پیش دارد. مثلا یکی از مشکلات این روش این است به برای به دست آوردن نوار مغزی بیماران شرکت کننده در این تحقیق از یک روش تهاجمی استفاده شده است.
مایزل یک نظریهپرداز عصبشناس است که سعی دارد بر مبنای نظریههای مختلف دریابد که چگونه تشنجهای صرعی از یک فعالیت غیرعادی کوچک مغزی شروع شده و تبدیل به یک حالت کاملا فلجکننده برای بیمار میشود. او میگوید که یادگیری ماشین به او در درک و توسعهی نظریهها کمک میکند. او میتواند نظریهی خود را در یک مدل یادگیری ماشین پیاده کند و ببیند که آیا این نظریه باعث بهتر شدن پیشبینیها میشود یا در جهت عکس عمل میکند. او میگوید:
اگر این روش جواب بدهد، یعنی نظریهی من درست است.
استفاده عملی از یادگیری ماشین مستلزم داشتن دسترسی به منابع دادهای وسیع است

یادگیری ماشین نمیتواند تمام مسائل اصلی علوم اعصاب را حل کند. عملکرد یادگیری ماشین ممکن است به دلیل کیفیت پایین اطلاعات دریافتی توسط fMRI محدود شود.
گیل وراکو، دانشمند علوم رایانهای که ابزار یادگیری ماشین را برای علوماعصاب توسعه داده است، میگوید:
حتی اگر ما تعداد بیشماری دادههای تصویری داشته باشیم، در آن صورت نیز نمیتوانیم یک پیشبینی کامل و دقیق داشته باشیم، زیرا پروسههای به دست آوردن این اطلاعات معیوب هستند.
اما بیشتر عصبشناسان معتقد هستند که ورود یادگیری ماشین به حوزهی علوم اعصاب باعث شفافیت بیشتری شده است. همچنین از یادگیری ماشین میتوان برای پیدا کردن راهحلی برای مشکل «مقایسهی چندگانه» در علوم اعصاب استفاده کرد. این عبارت در مواردی به کار میرود که محققان به دنبال دست یافتن به نتیجهای مهم از لحاظ آماری در میان دادهها هستند. با استفاده از یادگیری ماشین، پیشبینی شما در مورد رفتار مغز یا درست است و یا نادرست. وراکو میگوید که «پیشبینی» چیزی است که تحت کنترل ما قرار دارد.
دسترسی به منابع عظیم اطلاعاتی میتواند عصبشناسان را قادر کند تا تحقیقات بر روی رفتارهای مغزی را در بیرون از محیط آزمایشگاه نیز دنبال کنند. هیومن در این ارتباط میگوید:
تمام مدلهای مطالعاتی ما در مورد نحوهی کارکرد مغز در محیطی با شرایط مصنوعی بنا شده است. بنابرین ما مطمئن نیستیم که یک رفتار مغزی مشخص را در خارج از محیط آزمایشگاه و در دنیای واقعی شاهد باشیم.
اگر ما به نحوی بتوانیم به اطلاعات زیادی از رفتار مغز در زندگی روزمره دست یابیم، مثلا با استفاده از یک دستگاه ثبت نوارمغزی همراه، در آن صورت یادگیری ماشین میتواند به جستجوی الگوهای رفتاری مغز بپردازد، بدون این که به آزمایشات تصنعی نیازی باشد.
و در نهایت یک استفادهی دیگر برای برنامههای یادگیری ماشین در علوم اعصاب میتوان متصور شد، با اینکه شاید کمی تخیلی به نظر برسد. ما میتوانیم با مطالعهی رفتار مغز توسط یادگیری ماشین، برنامههای بهتری برای یادگیری ماشین بسازیم. بزرگترین پیشرفت روی داده در ۱۰ سال گذشته در تکنولوژی یادگیری ماشین، ایدهای با نام «شبکههای عصبی پیچیده» است، که گوگل با استفاده از آن میتواند اشیای موجود در عکسها را تشخیص دهد. این شبکههای عصبی از تئوریهای عصبشناسی نشئت میگیرند. پس هر چه بیشتر به بررسی رفتارهای مغزی با یادگیری ماشین بپردازیم، خود این روش نیز پیچیدهتر و باهوشتر میشود. سپس، برنامههای ارتقا یافتهی یادگیری ماشین دوباره میتوانند برای بررسی مغز مورد استفاده قرار گیرند و در این صورت دانش ما از علوم اعصاب بیشتر میشود.
همچنین محققان شاید بتوانند با استفاده از یادگیری ماشین، رویاهای انسان را دوباره بازآفرینی کنند. ممکن است در حین فرآیند بررسی رفتارهای مغزی، لازم باشد برنامهی یادگیری ماشین، فعالیتهای مغزی را شبیهسازی کند. وراکو میگوید:
ما نمیخواهیم مردم این گونه تصور کنند که ما به دنبال ساخت ماشینهای ذهنخوان هستیم. هدف ما این است که به مدلهای رایانهای پیچیدهتری برای درک رفتار مغز دست یابیم. من فکر میکنم که روزی به این هدف خواهیم رسید.
[ad_2]
لینک منبع
بازنشر: مفیدستان
عبارات مرتبط با این موضوع
خاتمه جهان با ظهور هوش مصنوعی؟ آکاوب سایت دیجیاتو تابحال شخصیت های معروفی در رابطه با هوش مصنوعی به اظهار نظر پرداخته محمدرضا فرزادپور همه چیز درباره هوش مصنوعیبالاخره آیا امکان ساخت یک هوش مصنوعی واقعی وجود دارد؟ و اگر امکان دارد ما چقدر به آن کامپیوترها در حال تکامل اند ولی آیا هوشمند هستند؟ …کامپیوترهادرحالبیگ بنگ احتمال دارد کامپیوترها در انجام برخی کارها بهتر از انسان ها عمل کنند ولی نکته علوم شناختی ویکیپدیا، دانشنامهٔ آزادعلومشناختیمیانرشتهای فیزیک کاربردی هوش مصنوعی زیستاخلاق بیوانفورماتیک زیستجغرافیاهارپ چیست؟ شیعه نیوز با این تفاوت که رادیو ترموگرافی سیستمی است که با قدرتی به کوچکی ٣٠ وات لایه های زیر بیولوژیوسیعترین کاربرد بالقوه این نوع درمان ، تولید سلولها و بافتهایی است که میتوانند الفبای زندگیهمانطور که می دانید، درخت لیمو در دو نوع لیمو شیرین و لیموترش شناخته شده است شما می شیردهی ویکیپدیا، دانشنامهٔ آزادشیردهیشیردهی یا تغذیه با شیر مادر عمل تغذیه نوزاد و یا طفل خردسال توسط شیر مادر به طور دارویــن و دروغ بزرگ کمیته مهندسی رباتیک ، گامی …دارویــنودروغبزرگحال یک سوال اساسی این است که چند درصد احتمال می رود کارگردانی با بیش از سال سابقه روزی ده عدد فندق بخورید، خواص فندق، فواید فندق، …جام جم آنلاین به گفته یک متخصص تغذیه ، با مصرف دانه فندق هرفرد میتواند بخش عمده محمدرضا فرزادپور همه چیز درباره هوش مصنوعی بالاخره آیا امکان ساخت یک هوش مصنوعی واقعی وجود دارد؟ و اگر امکان دارد ما چقدر به آن نزدیک دانستنی جذاب پیرامون مغز انسان زومیت دانستنیجذاب خصوصیات فیزیکی در این بخش اطلاعات با ارزشی پیرامون خصوصیات فیزیکی مغز انسان در اختیارتان علوم شناختی ویکیپدیا، دانشنامهٔ آزاد علومشناختی میانرشتهای فیزیک کاربردی · هوش مصنوعی زیستاخلاق · بیوانفورماتیک · زیستجغرافیا کامپیوترها در حال تکامل اند ولی آیا هوشمند هستند؟ کامپیوترهادر بیگ بنگ احتمال دارد کامپیوترها در انجام برخی کارها بهتر از انسان ها عمل کنند ولی نکته بیولوژی دید کلی اسکلت بدن از تعداد زیادی استخوان تشکیل شده است که بعضی از آنها فرد و بعضی دیگر زوج شیردهی ویکیپدیا، دانشنامهٔ آزاد شیردهی شیردهی یا تغذیه با شیر مادر عمل تغذیه نوزاد و یا طفل خردسال توسط شیر مادر به طور مستقیم توسط هارپ چیست؟ شیعه نیوز با این تفاوت که رادیو ترموگرافی سیستمی است که با قدرتی به کوچکی ٣٠ وات لایه های زیر زمینی را الفبای زندگی همانطور که می دانید، درخت لیمو در دو نوع لیمو شیرین و لیموترش شناخته شده است شما می توانید تکنولوژی
لینک منبع :خواندن مغز انسان با هوش مصنوعی امکانپذیر است